Python实战案例,Python脚本,Python实现批量下载百度图片
2021年8月13日 浏览:2084 评论:2 收藏:2
前言
今天我们就利用python脚本实现批量下载百度图片。直接开整~
如果有正在跟我一样的自学的朋友,需要我本篇的代码或者其他的Python学习资料可以加Python新手学习交流群:594356095添加助理直接获取
效果展示
编写思路:
1.获取图片的url链接
首先,打开百度图片首页,注意下图url中的index
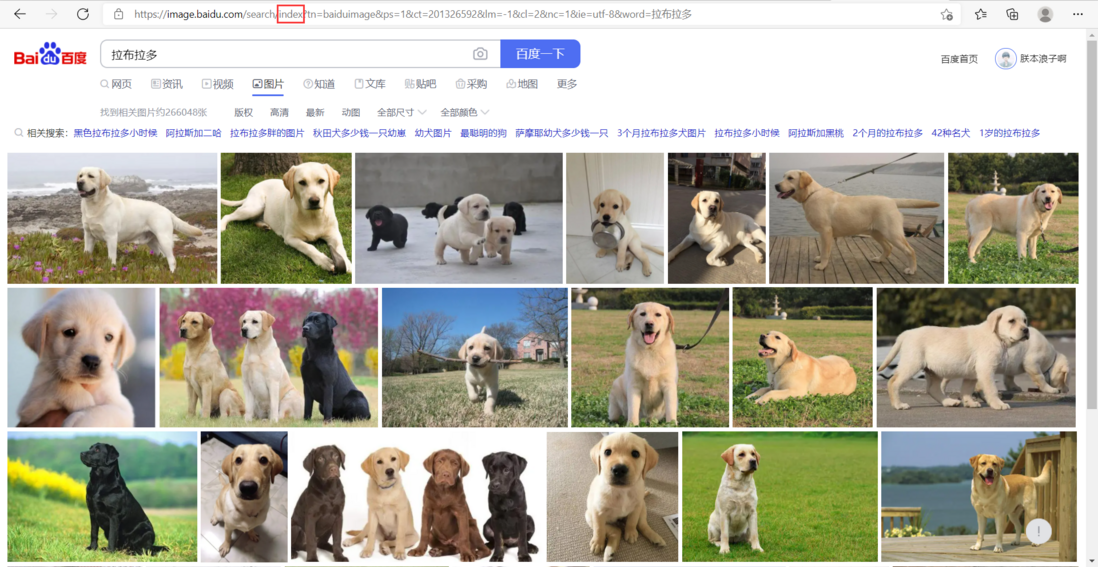
接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片!
然后,右键检查网页源代码,直接(ctrl+F)搜索 objURL
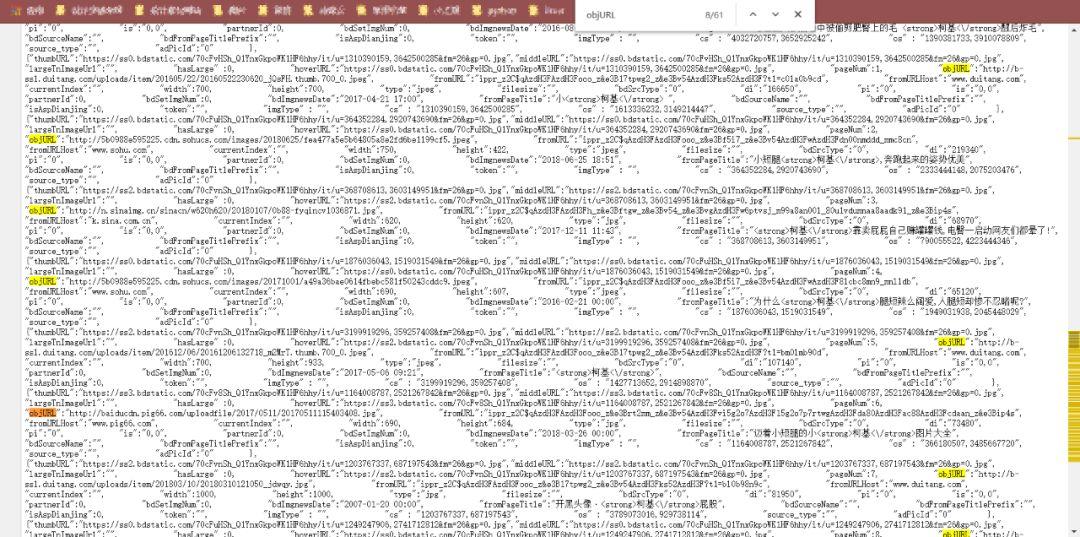
这样,我们发现了需要图片的url了。
2.把图片链接保存到本地
现在,我们要做的就是将这些信息爬取出来。
注:网页中有objURL,hoverURL…但是我们用的是objURL,因为这个是原图
正则表达式获取objURL
results = re.findall('"objURL":"(.*?)",', html)
源码展示:
1.获取图片url代码:
# 获取图片url连接
for i in range(int(pn)): # 1.获取网页
print('正在获取第{}页'.format(i+1)) # 百度图片首页的url
# name是你要搜索的关键词
# pn是你想下载的页数
url = 'https://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%s&pn=%d' %(name,i*20)
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4843.400 QQBrowser/9.7.13021.400'} # 发送请求,获取相应
response = requests.get(url, headers=headers)
html = response.content.decode() # print(html)
# 2.正则表达式解析网页
# "objURL":"http://n.sinaimg.cn/sports/transform/20170406/dHEk-fycxmks5842687.jpg"
results = re.findall('"objURL":"(.*?)",', html) # 返回一个列表
# 根据获取到的图片链接,把图片保存到本地
save_to_txt(results, name, i)</pre>
2.保存图片到本地代码:
# 保存图片到本地
j = 0
# 在当目录下创建文件夹
if not os.path.exists('./' + name):
os.makedirs('./' + name) # 下载图片
for result in results: print('正在保存第{}个'.format(j)) try:
pic = requests.get(result, timeout=10)
time.sleep(1) except: print('当前图片无法下载')
j += 1
continue
# 可忽略,这段代码有bug
# file_name = result.split('/')
# file_name = file_name[len(file_name) - 1]
# print(file_name)
#
# end = re.search('(.png|.jpg|.jpeg|.gif)/pre>, file_name)
# if end == None:
# file_name = file_name + '.jpg'
# 把图片保存到文件夹
file_full_name = './' + name + '/' + str(i) + '-' + str(j) + '.jpg'
with open(file_full_name, 'wb') as f:
f.write(pic.content)
j += 1
核心代码:
pic = requests.get(result, timeout=10)
f.write(pic.content)
3.主函数代码:
# 主函数if __name__ == '__main__':
name = input('请输入你要下载的关键词:')
pn = input('你想下载前几页(1页有60张):')
get_parse_page(pn, name)
文章到这里就结束了,感谢你的观看,Python实用脚本系列,下篇文章分享天气查询应用
为了感谢读者们,我想把我最近收藏的一些编程干货分享给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
⑥ 两天的Python爬虫训练营直播权限
All done~详见个人简介或者私信获取完整源代码。。

点赞 评论 2 收藏 2

关注



















