2023年人工智能训练与推理工作站、服务器、集群硬件配置推荐
ChatGPT出色的表现,带动了人工智能的应用加速,人工智能大模型、多模态机器学习,多模态大模型+物联网等各个行业的专业应用,算力不够是最大的不足,市场上A100/A800/H100/H800的GPU卡的缺货、涨价等,成本上升,不得不考虑GPU替代型号的、性能接近A100/H100的方案
(一)GPU计算卡选型
下面是目前市场上可选GPU卡之间,基于深度学习训练与推理的关键技术指标对比
No |
关键指标 |
单位 |
H100 PCIe |
A100 |
RTX 6000 Ada |
A100 |
Tesla V100 |
RTX4090 |
1 |
显存 |
GB |
80 |
80 |
48 |
40 |
32 |
24 |
2 |
显存带宽 |
GB/s |
2048 |
2048 |
960 |
1536 |
897 |
1008 |
3 |
CUDA FP16 |
Tflops |
204.87 |
77.97 |
91.06 |
77.97 |
28.26 |
82.58 |
4 |
CUDA FP32 |
Tflops |
51.22 |
19.49 |
91.06 |
19.49 |
14.13 |
82.58 |
5 |
Tensor INT8 |
TOPS |
3201 |
609 |
609 |
125 |
1452 |
|
6 |
Tensor FP16 |
Tflops |
1601 |
305 |
711 |
305 |
125 |
726 |
从上述表里看,RTX6000 Ada 48GB与A100 80GB对比
No |
关键指标 |
A100 80GB |
RTX6000 Ada |
备注 |
1 |
显存 |
80GB |
48GB |
A100更大 |
2 |
显存带宽 |
2048GB/s |
960GB/s |
A100更大 |
3 |
CUDA FP16 |
77.97Tflops |
91.06Tflops |
RTX6000Ada更快 |
4 |
CUDA FP32 |
19.49Tflops |
91.06Tflops |
RTX6000Ada更快 |
5 |
Tensor INT8 |
609Tflops |
1423Tflops |
RTX6000Ada更快 |
6 |
成本 |
成本高 |
成本低 |
RTX6000Ada 更便宜 |
RTX6000Ada(48GB)与RTX4090(24GB)对比,前者显存是48GB,作为自然语言处理,显存越大越合适,
因此 综上说述,基于自然语言处理应用,无论是做训练还是推理,RTX6000Ada是一款非常合适的A100备用型号
(二)GPU AI集群系统相关产品介绍
下面是西安坤隆计算机科技有限公司提供的基于ChatGPT科研型AI集群配置方案
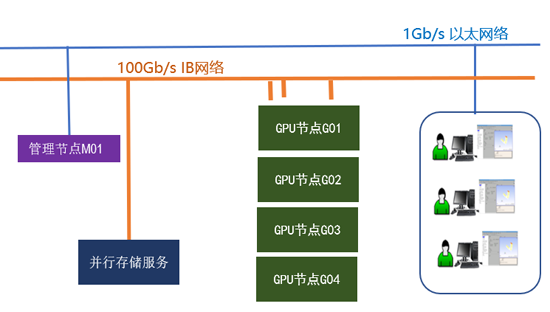
(1)GPU计算服务器(计算节点)

相关机型:UltraLAB GX658
技术特点:
GPU 配备最高8块nvidia RTX/Tesla系列GPU计算卡,
CPU 采用intel第3代Xeon可扩展处理器,支持PCIe 4.0 x16接口
网口配备100G IB网口,
硬盘采用SSD,
保证硬件配置计算更强、io带宽更高、整机性能全方位优化,保证多用户多任务神经元完美计算能力。
(2)存储服务器(存储节点)
相关机型:UltraLAB N650C(24盘位)
技术特点:
CPU 采用intel Xeon第3代可扩展处理器,最大80核,可满足60台计算节点同步访问
高速缓存盘:配备M2.SSD确保数据处理的高速读写(读写3G/s以上)及超低io延迟、
配备并行存储:数据备份安全可靠、最大容量到378TB(24盘位,3通道)
网口:配备双100G光口,
整机性能全方位优化 支持远程操作、远程管理,系统管理员和使用者直接在办公室甚至异地进行操作
(3)SLURM作业调度软件
SLURM 是优秀的开源作业调度系 统,和 Torque PBS 相比,SLURM 集成度更高,对 GPU 和 MIC 等加速设备支持更好
Slurm是适应不同计算规模Linux集群的资源管理和调度软件。它提供高效的资源与作业管理。包括状态监控、资源管理、作业调度和用量记账
支持更多的仿真模拟软件,
支持定制不同的应用软件的集群系统扩展
(三)UltraLAB GPU超算集群硬件配置推荐2023v2
方案1 CX650 GPU超算集群配置推荐
计算节点5个
GPU卡:40块RTX6000Ada,总显存1.92TB,
集群FP32单精度浮点算力:3640Tflops (3.6PTflops)
配置方案
NO |
货物名称 |
型号 |
数量 |
1 |
GPU计算服务器GX658 |
2*Xeon银4316(40核2.8Ghz )/512GB DDR4 /8块RTX6000 Ada 48GB /1.92TB SSD /4U机架式/100G IB光口/无显示器 |
5 |
2 |
存储服务器N650C |
2颗Xeon 4314(32核2.3Ghz )/192GB DDR4 /QT1000 /960GB SSD系统盘+7.68TB高速缓存盘(2块) +126TB并行存储/4U机架式/100G IB光口/27"4K图显 |
1 |
3 |
计算交换机 |
36个100G IB ,光口 |
1 |
管理交换机 |
48口千兆以太,电口 |
1 |
|
4 |
服务器机柜 |
42U,含PDU、托盘 |
1 |
5 |
KVM |
16口 HDMI KVM切换器 |
1 |
6 |
集群系统 |
CentOS/Ubuntu、作业调度管理 |
1 |
7 |
深度学习框架 |
Tensorflow、Pytorch… |
1 |
合计 |
¥3,210,500元 (321万) |
方案2 CX650 GPU超算集群配置推荐
计算节点10个
GPU卡:80块RTX6000Ada,总显存3.84TB,
集群FP32单精度浮点算力:7280Tflops (7.2PTflops)
配置方案
NO |
货物名称 |
型号 |
数量 |
1 |
GPU计算服务器GX658 |
2*Xeon银4316(40核2.8Ghz )/512GB DDR4 /8块RTX6000 Ada 48GB /1.92TB SSD /4U机架式/100G IB光口/无显示器 |
10 |
2 |
存储服务器N650C |
2颗Xeon 4314(32核2.3Ghz )/192GB DDR4 /QT1000 /960GB SSD系统盘+7.68TB高速缓存盘(2块) +126TB并行存储/4U机架式/100G IB光口/27"4K图显 |
1 |
3 |
计算交换机 |
36个100G IB ,光口 |
1 |
管理交换机 |
48口千兆以太,电口 |
1 |
|
4 |
服务器机柜 |
42U,含PDU、托盘 |
2 |
5 |
KVM |
16口 HDMI KVM切换器 |
1 |
6 |
集群系统 |
CentOS/Ubuntu、作业调度管理 |
1 |
7 |
深度学习框架 |
Tensorflow、Pytorch… |
1 |
合计 |
¥6,200,500元 (620万) |
方案3 CX650 GPU超算集群配置推荐
计算节点30个
GPU卡:240块RTX6000Ada,总显存11.5TB,
集群FP32单精度浮点算力:21840Tflops (21.8PTflops)
配置方案
NO |
货物名称 |
型号 |
数量 |
1 |
GPU计算服务器GX658 |
2*Xeon银4316(40核2.8Ghz )/512GB DDR4 /8块RTX6000 Ada 48GB /1.92TB SSD /4U机架式/100G IB光口/无显示器 |
30 |
2 |
存储服务器N650C |
2颗Xeon 4314(32核2.3Ghz )/192GB DDR4 /QT1000 /960GB SSD系统盘+7.68TB高速缓存盘(2块) +126TB并行存储/4U机架式/100G IB光口/27"4K图显 |
2 |
3 |
计算交换机 |
36个100G IB ,光口 |
1 |
管理交换机 |
48口千兆以太,电口 |
1 |
|
4 |
服务器机柜 |
42U,含PDU、托盘 |
5 |
5 |
KVM |
16口 HDMI KVM切换器 |
2 |
6 |
集群系统 |
CentOS/Ubuntu、作业调度管理 |
1 |
7 |
深度学习框架 |
Tensorflow、Pytorch… |
1 |
合计 |
¥18,525,800元 (1852万) |
GPU超算集群应用领域
人工智能训练、推理集群计算
分子动力学、蛋白质折叠、
电磁仿真时域求解
数字孪生超高分可视化
技术服务
本文所提供配置也可根据实际情况,进行调整 ,我们技术保证
-整个集群开机即用
-三年质保
-365*7*24小时在线技术支持
上述所有配置,代表最新硬件架构,同时保证是最完美,最快,如有不符,可直接退货
欲咨询机器处理速度如何、技术咨询、索取详细技术方案,提供远程测试,请联系
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800,18601230361
微信:





















