大模型技术在自动驾驶中的应用
 2023年6月26日 17:01
2023年6月26日 17:01浏览:2452 收藏:1

人工智能(Artificial Intelligence,简称AI)是一种计算机科学技术,旨在使计算机能够模仿、学习和执行人类智能任务。它涉及到多个不同的子领域,包括机器学习、自然语言处理、计算机视觉和强化学习等。通过使用大数据、算法、神经网络等技术,人工智能可以通过分析和理解数据来建立模型,并对新数据进行决策和预测,从而实现某些特定的任务。与传统计算机程序不同的是,人工智能可以根据以前的经验和学习来改进自己的性能,在某些情况下能够比人类更准确和高效地完成任务。人工智能被广泛应用于各种领域,例如医疗保健、金融、交通运输、制造业、社交媒体、游戏和安全等。
大模型通常指的是由数亿至数千亿个参数组成的深度学习模型。这些模型需要巨大的计算资源和存储空间,因此非常昂贵且能够运行的硬件配置也要足够强大。大型模型代表了人工智能领域最先进的技术,广泛应用于自然语言处理、图像识别、语音识别和推荐系统等领域。拥有更多的参数可以提高模型的准确性和精度,但同时也会导致更复杂的训练过程、更长的训练时间和更高的硬件成本。GPT-3就是一种例子,它具有1750亿个参数,在人工智能技术中占据着重要的地位。
神经网络(Neural Network)是一种复杂的数学模型,建立在类比生物大脑神经元之间传递信息的基础上。它由许多相互连接并按层次结构排列的处理单元组成,这些单元称为“神经元”。神经网络通过输入数据、计算和传递信号来进行训练,以便预测或分类未知的数据。
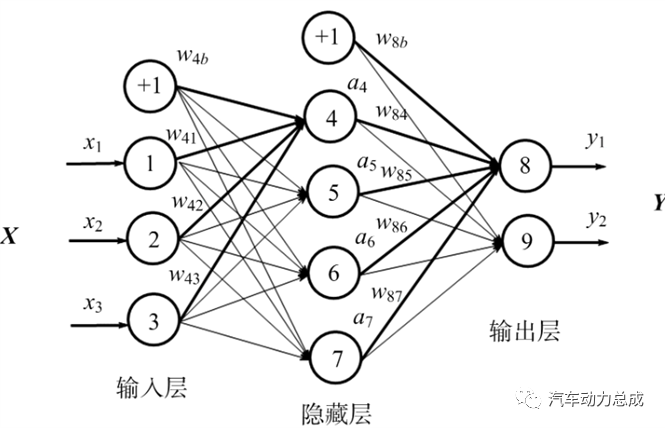
神经网络被广泛应用于图像识别、语音识别、自然语言处理等领域,具有很强的学习和适应能力。在神经网络中,不同层次的神经元会对输入数据进行各种变换和筛选,从而提取出不同级别的特征,以便对其进行进一步的分析和处理。通过反向传播算法(backpropagation),神经网络可以根据输出误差调整每个神经元之间的连接权重,从而持续优化模型的性能。
1.
反向传播算法(Backpropagation):
通过计算输出误差并反向逐层调整权重和偏差,以最小化误差来训练网络。
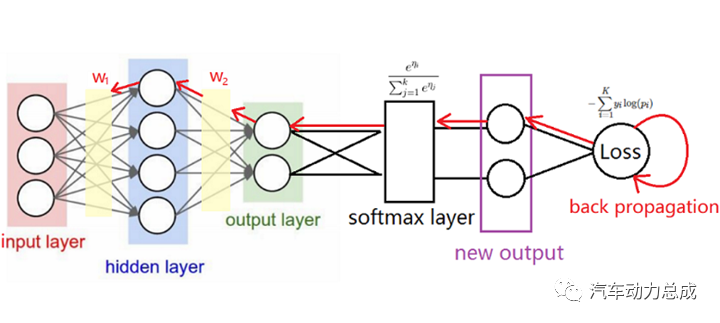
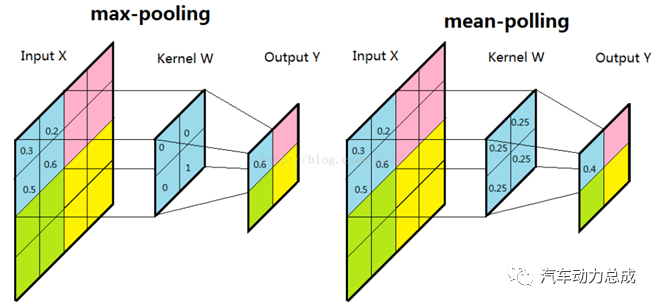
2.卷积神经网络(Convolutional Neural Network, CNN):专门用于处理图像和视频等数据的神经网络,包括卷积层、池化层和全连接层等组成部分。
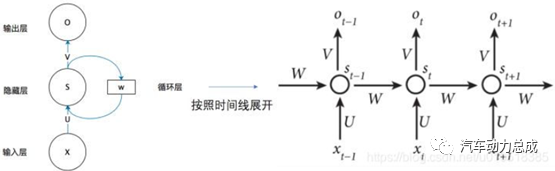
3.循环神经网络(Recurrent Neural Network, RNN):具有序列记忆能力的神经网络,可以对连续的输入数据进行处理,并自动更新状态。
4.长短时记忆网络(Long Short-Term Memory, LSTM):一种特殊的RNN模型,可克服传统RNN面临的梯度消失问题,适用于学习长期依赖关系。
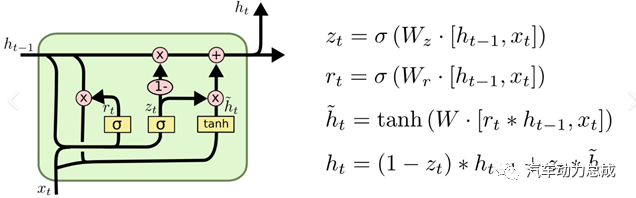
5.生成对抗网络(Generative Adversarial Networks, GANs):由生成器和判别器两个对抗模型组成,通过不断优化,使生成器生成足够真实的数据,从而欺骗判别器认为其为真实数据。
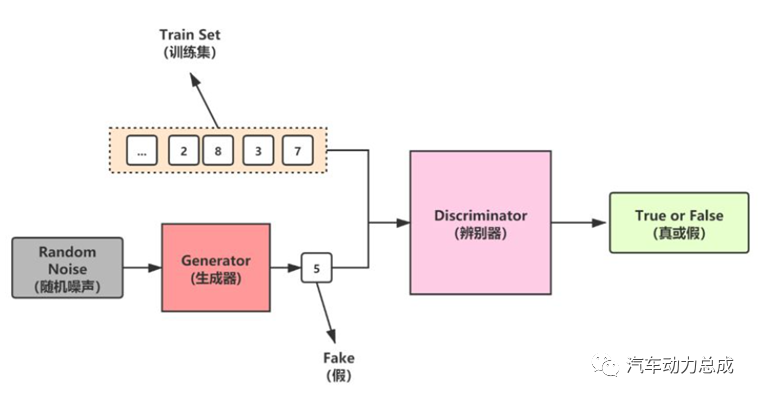
6.自编码器(Autoencoder):利用一个编码器将输入数据压缩为潜在表示,再使用一个解码器将其还原为原始数据,可以用于特征提取、降噪和图像增强等领域。
以上是常见的一些神经网络算法,每个算法都有不同的应用场景和优缺点。
在自动驾驶领域,大模型的应用可以提高自动驾驶系统的感知与决策等方面的能力。具体来说,大模型可以通过先前建立于大量真实交通数据上的预训练,在车辆、行人、道路标志、红绿灯等多种场景下自动生成语义信息,进而充分理解并掌握城市交通中各种复杂情境,从而有效地提升自动驾驶车辆的安全性和可靠性。
例如,大规模预训练的模型可以被用来检测行人、障碍物、车辆等,以及进行精确的路标识别和交通信号判断,在自动驾驶系统中大大提高了感知系统的准确性;另外,大模型也可以被应用于路径规划、车速控制、转向、制动等决策过程,从而更好地适应不同的路况和特定场景(如高速公路、城市交通拥堵等)。总之,大模型作为一种强大的AI技术,在自动驾驶领域中具有非常巨大的潜力。
许多汽车公司正在探索如何利用大模型在自动驾驶领域中提高车辆的安全性和可靠性,以下是其中一些主要的汽车公司:
特斯拉(Tesla):特斯拉利用深度学习技术来实现自动驾驶功能,并采用了大量的神经网络模型。
Waymo:Waymo 是 Alphabet 旗下的一家自动驾驶子公司,在车辆的感知、决策和控制等方面均应用了大规模的深度学习模型。
英伟达(Nvidia):英伟达开发并销售了一种名为 NVIDIA DRIVE 的平台,它包括处理器和软件工具,可用于构建自动驾驶汽车所需的各种计算机视觉、计算机图形学和媒体处理应用程序,包括大规模深度学习模型。
Mobileye 也是自动驾驶技术的龙头企业之一,其使用了基于深度学习的算法、传感器与定位技术等,支持各种不同类型的自动驾驶场景。
通用汽车(General Motors):通用汽车正在与 Cruise 合作,通过深度学习技术来提高自动驾驶汽车的性能。
奔驰(Mercedes-Benz):奔驰推出名为 Mercedes-Benz Intelligent Drive 的方案,该方案基于神经网络技术,可为车辆提供先进的自动驾驶功能。
斯巴鲁(Subaru):斯巴鲁正在开发名为 EyeSight 的自动驾驶技术平台,其中包括大量的深度学习算法,可以帮助车辆实现更准确的感知和决策。
算法是决定自动驾驶车辆感知能力的核心要素。当前主流的自动驾驶模型框架分为感知、规划决策和执行三部分。感知模块是自动驾驶系统的眼睛,核心任务包括对采集图像进行检测、分割等,是后续决策层的基础,决定了整个自动驾驶模型的上限,在自动驾驶系统中至关重要。感知模块硬件部分主要为传感器,软件为感知算法,其中算法是决定自动驾驶车辆感知能力的核心要素。
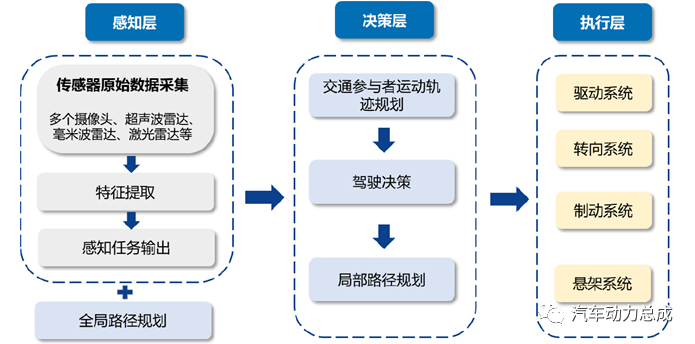
神经网络模型的应用驱动感知算法高速发展,具体可以分为两类,一类是以CNN、RNN为代表的小模型,另一类是Transformer 大模型。
在自动驾驶感知模块中输入数据为图像,而图像具有高维数(对比时间序列通常只是一维向量),对其识别时需要设置大量输入神经元以及多个中间层,模型参数量大难以训练且消耗算力高,并可能带来过拟合的问题,基于这种思想,CNN卷积神经网络应运而生,本质上是在信息传入传统神经网络前先做一个特征的提取并进行数据降维,因此CNN 图像处理高纬度向量的任务上更加高效。CNN 能够高效率处理图像任务的关键在于其通过卷积层、池化层操作实现了降维,模型需要训练的参数量相比于 DNN 来说大幅降低,对硬件算力的要求也相对降低。CNN 能够高效率处理图像任务的关键在于其通过卷积层、池化层操作实现了降维,模型需要训练的参数量相比于 DNN 来说大幅降低,对硬件算力的要求也相对降低。
在自动驾驶场景下,感知还需要时序的信息来完成目标跟踪以及视野盲区预测等感知任
务。
循环神经网络 RNN 与 CNN 一样都是传统神经网络的扩展,相比于 CNN 在空间上进行拓展,RNN 是在时间上的扩展,可以用于描述时间上连续输出的状态。
例如自动驾驶场景中可能会出现前方大卡车造成遮挡,如果要判断视野盲区里是否有行人就需要结合被卡车遮挡前的信息,由此需要引入循环神经网络 RNN 对时序信息进行处理。
RNN 与 DNN 在结构上相近,区别在于 RNN 在隐藏层引入“循环”,即每一个隐藏层上的每一个记忆体(本质就是感知机)都与上一个时刻隐藏层上的所有记忆连接,这意味着某一时刻网络的输出除了与当前时刻的输入相关,还与之前某一时刻或某几个时刻的输出相关。
引入了循环的隐藏层叫做循环核,RNN 借助循环核提取时间特征,从而引入了时序上的相关性实现连续数据的预测。
但是RNN 的局限主要在于:
1)循环核需要存储,意味着硬件需要具备更大的缓存。
同时记忆体个数越多存储历史状态信息的能力越强、训练效果越好,但需要训练的参数量、消耗的资源也越多,二者共同制约 RNN,使其难以学到长时间距离的依赖关系。
2)RNN 并行能力受限,由于某一时刻网络的输出不但与当前时刻的输入相关,还与上一时刻的输出结果相关,因此 RNN 无法进行并行计算,使得计算效率非常受限。
Transformer 大模型的注意力机制成为自动驾驶感知算法的利器,它关键在于计算输入序列元素之间的关系权重,通过引入注意力(attention)机制。可以对注意力(attention)机制直观理解为“只关注重要的信息而非全部信息”,比如当我们视线扫过大片文字,注意力会停留在其中的关键词及关键词之间的逻辑关联上,而对其余信息则印象不深。自注意力机制中,Q、K、V 三个参数来自于同一个输入序列,用序列中所有元素向量的加权和来代表某一个元素的向量,因此自注意力机制可以捕捉输入数据中的长距离依赖关系,常用于特征提取。所谓“多头注意力机制”是一种并行计算的注意力方法,它将输入数据分成多个部分(称为“头”),然后分别计算各部分的注意力得分。这样做的好处是,不同的头可以关注输入数据的不同部分,从而捕捉到更多的特征。交叉注意力机制与自注意力机制的计算过程类似,核心区别在于交叉注意力机制中 Q 和 K/V 的来源不同,因此常被用来做不同序列之间的转换。Transformer 凭借优秀的长序列处理能力和更高的并行计算效率,2021 年由特斯拉引入自动驾驶领域。Transformer 与 CNN 相比最大的优势在于其泛化性更强。
感知可粗略分为获取数据、提取特征、完成感知任务三个环节,按照信息融合发生的环节自动驾驶感知技术可以分为前融合、特征融合以及后融合。特征级融合逐步取代后融合,BEV+Transformer 为当前主流方案;特征级融合方案相比于后融合数据损失小、相比于前融合的算力消耗低,自动驾驶感知技术从后融合向特征级融合迭代趋势明确,目前主流的方案是在 3/4D 空间中进行特征级融合。BEV(Bird's Eye View)鸟瞰图也可以称之为“上帝视角”,是一种用于描述感知世界的坐标系,在 BEV 空间中可以进行自动驾驶感知模块的前融合、特征级融合或者后融合。BEV 鸟瞰图仅是一种对感知世界的表达方式,因此其也可广泛应用在纯视觉方案、多传感器融合方案以及车路协同方案中。
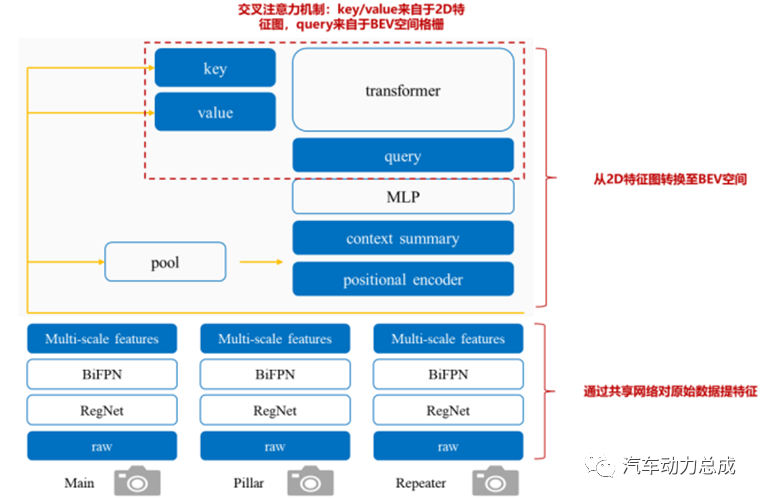

在 BEV 空间中做特征级融合早期的代表性算法为英伟达 2020 年提出的 LSS 算法,是基于深度分布估计进行 BEV 空间转换的开山之作。Transformer 交叉注意力机制对于 BEV 空间转换任务适配性较高,目前成为特斯拉、小鹏等 自动驾驶厂商主流的技术方案。下图为特斯拉基于 Transformer 的 BEV 空间转换架构。高精地图能够提供超视距、厘米级相对定位及导航信息,在数据和算法尚未成熟到脱图之前,尤其针对国内的复杂路况,其对主机厂实现高阶自动驾驶功能具有重要意义,现阶段国内主机厂实现城市领航辅助驾驶落地的主要基于高精度地图+单车感知的方案。
自动驾驶感知算法向 BEV+transformer 架构升级,助力城市领航辅助驾驶脱高精度地图。特斯拉 BEV 感知模型为特征级融合,极大的提高了模型在极端天气工况下的应对能力,BEV 鸟瞰图相当于自动驾驶车辆实施生成“活地图”,因而可以实现去高精度地图化。高精度地图方案在城市场景下缺陷明显,特斯拉 BEV+Transformer 方案为行业“脱图”提供了技术上的可行性,很大可能“轻地图,重感知”将成为行业发展的主流方向,而小鹏等国内自动驾驶厂商均提出“脱图”时间表。
在当前自动驾驶模型架构中将驾驶目标划分为感知、规划、控制三个大的模块,而端到端则打破模块之间的划分,直接输出最终的结果。现有的模型思路是感知模块输出 BEV 鸟瞰图(或者 Occupancy)的结果,规划和控制模块再依据 BEV 鸟瞰图结果进行预测和执行。而在端到端(end-to-end)模型中,输入数据是摄像头采集的到的视频流 raw-data,输出数据直接是如方向盘转角多少度的控制决策。端到端的思路更类似于人的驾驶过程,人的驾驶决策往往基于经验,司机驾驶车辆时并不会刻意对基于视觉/眼睛提供的信息进行分析,即不会去判断我看到了什么,也不会对看到的物体和状态做分析,驾驶员固有的“经验”所活跃的脑质皮层在一种“黑盒”的状态下,完成驾驶决策,并协调耳眼手脚,共同完成驾驶任务。
大模型技术将“场景-驾驶行为”的映射转变为“场景-车辆控制”的“端到端”式映射。深度强化学习(DRL)结合了深度学习算法的“感知能力”和强化学习算法的“决策能力”,为复杂驾驶场景的感知决策问题提供解决方案。其中,深度学习负责复杂驾驶场景的感知和特征提取如同人类的眼睛;强化学习部分通过马尔可夫决策过程完成推理、判断和决策如同人脑。
由于自动驾驶技术一直处于高速发展的阶段,许多企业都在积极探索和尝试不同的技术手段,在未来可能有更多的汽车公司在自动驾驶领域中利用大模型。
文章来源:汽车动力总成

技术邻APP
工程师必备
















![[案例专题]基于ICEM和Fluent的二维喷管非结构网格算例实例](https://img.jishulink.com/cimage/a2935f5023ce0e9831b5db828f22c7f1.jpg?image_process=resize,fw_576,fh_320,)







