数据挖掘中的数据预处理
数据预处理是数据挖掘过程中的一个重要步骤。它是指清理、转换和集成数据,以便为分析做好准备。数据预处理的目标是提高数据质量,使其更适合特定的数据挖掘任务。
数据预处理步骤
数据预处理是数据挖掘过程中的一个重要步骤,涉及清理和转换原始数据以使其适合分析。数据预处理中的一些常见步骤包括:
- 数据清理:这涉及识别和纠正数据中的错误或不一致,例如缺失值、异常值和重复项。可以使用各种技术进行数据清理,例如插补、删除和转换。
- 数据集成:这涉及组合来自多个来源的数据以创建统一的数据集。数据集成可能具有挑战性,因为它需要处理具有不同格式、结构和语义的数据。可以使用记录链接和数据融合等技术进行数据集成。
- 数据转换:这涉及将数据转换为合适的格式以供分析。数据转换中使用的常见技术包括规范化、标准化和离散化。标准化用于将数据缩放到公共范围,而标准化用于将数据转换为零均值和单位方差。离散化用于将连续数据转换为离散类别。
- 数据缩减:这涉及在保留重要信息的同时减小数据集的大小。可以通过特征选择和特征提取等技术实现数据缩减。特征选择涉及从数据集中选择相关特征的子集,而特征提取涉及将数据转换为较低维空间,同时保留重要信息。
- 数据离散化:这涉及将连续数据划分为离散的类别或间隔。离散化通常用于需要分类数据的数据挖掘和机器学习算法。离散化可以通过等宽分箱、等频分箱和聚类等技术来实现。
- 数据规范化:这涉及将数据缩放到一个通用范围,例如介于 0 和 1 之间或 -1 和 1 之间。归一化通常用于处理具有不同单位和尺度的数据。常见的规范化技术包括最小-最大规范化、z 分数规范化和十进制缩放。
数据预处理在保证数据质量和分析结果的准确性方面起着至关重要的作用。数据预处理中涉及的具体步骤可能因数据的性质和分析目标而异。
通过执行这些步骤,数据挖掘过程变得更加高效,结果也变得更加准确。
数据挖掘中的预处理
数据预处理是一种数据挖掘技术,用于将原始数据转换为有用且高效的格式。
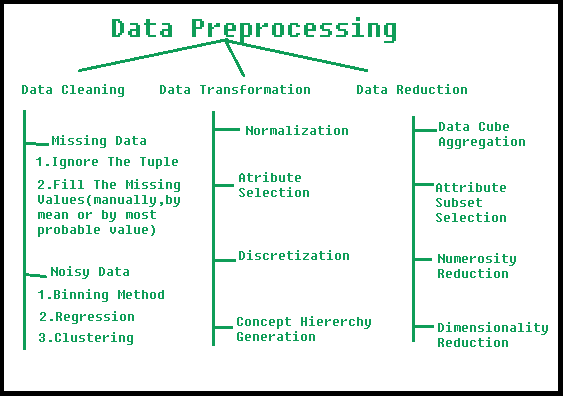 数据预处理涉及的步骤
数据预处理涉及的步骤
1. 数据清理:数据可能有许多不相关和缺失的部分。为了处理这部分,完成了数据清理。它涉及处理缺失数据、嘈杂数据等。
- 缺失数据:当数据中缺少某些数据时,会出现这种情况。它可以通过多种方式处理。
- 他们之中有一些是:
- 忽略元组:仅当我们拥有的数据集非常大并且元组中缺少多个值时,此方法才适用。
- Fill the Missing values(填充缺失值):有多种方法可以完成此任务。您可以选择按属性平均值或最可能值手动填充缺失值。
- 干扰数据:干扰数据是机器无法解释的无意义数据。它可能是由于数据收集错误、数据输入错误等而生成的。可以通过以下方式处理它:
- Binning Method(分箱方法):此方法适用于已排序的数据,以便使其平滑。将整个数据分成大小相等的段,然后执行各种方法完成任务。每个分段都是单独处理的。可以用其平均值或边界值替换 segment 中的所有数据,以完成任务。
- 回归:这里可以通过将数据拟合到回归函数来使数据变得平滑。使用的回归可以是线性的(具有一个自变量)或多个的(具有多个自变量)。
- 聚类:此方法将集群中的相似数据分组。异常值可能未被检测到,或者会落在集群之外。
2. 数据转换:采取此步骤是为了将数据转换为适合挖掘过程的适当形式。这涉及以下方式:
- 规范化:这样做是为了在指定范围(-1.0 到 1.0 或 0.0 到 1.0)内缩放数据值
- Attribute Selection:在此策略中,从给定的属性集构建新属性以帮助挖掘过程。
- 离散化:这样做是为了用区间级别或概念级别替换数字属性的原始值。
- 概念层次结构生成:此处,属性在层次结构中从较低级别转换为较高级别。例如,属性 “city” 可以转换为 “country”。
3. 数据缩减:数据缩减是数据挖掘过程中的关键步骤,涉及在保留重要信息的同时减小数据集的大小。这样做是为了提高数据分析的效率并避免模型过度拟合。数据缩减涉及的一些常见步骤包括:
- Feature Selection(特征选择):这涉及从数据集中选择相关特征的子集。执行特征选择通常是为了从数据集中删除不相关或冗余的特征。可以使用各种技术来完成,例如相关性分析、互信息和主成分分析 (PCA)。
- 特征提取:这涉及将数据转换为低维空间,同时保留重要信息。当原始特征具有高维和复杂时,通常会使用特征提取。可以使用 PCA、线性判别分析 (LDA) 和非负矩阵分解 (NMF) 等技术来完成。
- 采样:这涉及从数据集中选择数据点的子集。采样通常用于减小数据集的大小,同时保留重要信息。可以使用随机抽样、分层抽样和系统抽样等技术来完成。
- 聚类:这涉及将相似的数据点分组到集群中。聚类通常用于通过将相似的数据点替换为具有代表性的质心来减小数据集的大小。可以使用 k-means、分层聚类和基于密度的聚类等技术来完成此操作。
- 压缩:这涉及在保留重要信息的同时压缩数据集。压缩通常用于减小数据集的大小,以便进行存储和传输。可以使用小波压缩、JPEG 压缩和 gif 压缩等技术来完成。
如何使用数据预处理?
我们之前已经指出,这是数据预处理在机器学习和 AI 应用程序开发的早期阶段很重要的原因之一。在 AI 环境中,应用数据预处理是为了优化用于清理、转换和构建数据的方法,从而以更少的计算能力提高新模型的准确性。
一个出色的数据预处理步骤将有助于开发一组组件或工具,这些组件或工具可用于快速构建一组想法的原型,甚至可以运行实验来改进业务流程或客户满意度。例如,预处理可以通过增强用于分类的客户年龄范围来增强推荐引擎的数据排列方式。
它还可以使开发和增强数据的过程更容易,以获得更增强的 BI,这对业务有益。例如,客户的小规模、类别或区域在不同区域可能具有不同的行为。将数据后端处理为正确的格式可能使 BI 团队能够将此类发现集成到 BI 控制面板中。
从广义上讲,数据预处理是 Web 挖掘的一个子过程,用于客户关系管理 (CRM)。通常可以对 Web 使用日志进行预处理,以获得有意义的数据集,这些数据集称为用户事务,实际上是一组 URL 引用。可以存储会话以识别用户身份以及请求的网站及其使用顺序和时间。一旦从原始数据中提取出来,这些就会提供更有意义的信息,可用于消费者分析、产品促销或定制等。
结论
数据预处理在数据质量检查和分析检查中都起着核心作用。通过这种方式,数据挖掘过程变得有效,并且这些步骤得到的结果是准确的。准确地说,数据预处理过程中遵循的过程可能因数据集而异,或者取决于所需的分析。
有关数据挖掘中数据预处理的常见问题解答 – 常见问题解答
什么是数据预处理?
数据预处理提高了数据的质量,从而使其适合分析。它最大限度地减少了错误、变化和重复,从而提高了获得正确结果的可能性。
数据清洗过程中可以采用哪些方法?
其中一些是插补的缺失数据机制、可以删除的复制实例的情况、分箱或回归的干扰数据,以及分组的类似数据点。
数据转换如何协助数据挖掘?
就数据分析而言,数据转换涉及将数据转换为更有用的形式的过程。规范化、离散化和概念层次结构生成是用于对齐数据以增强挖掘的一些方法。



















